

【導(dǎo)讀】日益增長的數(shù)據(jù)加速需求對硬件平臺提出了越來越高的要求,F(xiàn)PGA作為一種可編程可定制化的高性能硬件發(fā)揮著越來越重要的作用。近年來,高端FPGA芯片采用了越來越多的Hard IP去提升FPGA外圍的數(shù)據(jù)傳輸帶寬以及存儲器帶寬。但是在FPGA內(nèi)部,可編程邏輯部分隨著工藝提升而不斷進(jìn)步的同時,內(nèi)外部數(shù)據(jù)交換性能的提升并沒有那么明顯,所以FPGA內(nèi)部數(shù)據(jù)的交換越來越成為數(shù)據(jù)傳輸?shù)钠款i。
為了解決這一問題,Achronix 在其最新基于臺積電(TSMC)7nm FinFET工藝的Speedster7t FPGA器件中包含了革命性的創(chuàng)新型二維片上網(wǎng)絡(luò)(2D NoC)。這種2D NoC如同在FPGA可編程邏輯結(jié)構(gòu)之上運(yùn)行的高速公路網(wǎng)絡(luò)一樣,為FPGA外部高速接口和內(nèi)部可編程邏輯的數(shù)據(jù)傳輸提供了大約高達(dá)27Tbps的超高帶寬。
作為Speedster7t FPGA器件中的重要創(chuàng)新之一,2D NoC為FPGA設(shè)計提供了幾項重要優(yōu)勢,包括:
● 提高設(shè)計的性能,讓FPGA內(nèi)部的數(shù)據(jù)傳輸不再成為瓶頸。
● 節(jié)省FPGA可編程邏輯資源,簡化邏輯設(shè)計,由NoC去替代傳統(tǒng)的邏輯去做高速數(shù)據(jù)傳輸和數(shù)據(jù)總線管理。
● 增加了FPGA的布線資源,對于資源占用很高的設(shè)計有效地降低布局布線擁塞的風(fēng)險。
● 實(shí)現(xiàn)真正的模塊化設(shè)計,減小FPGA設(shè)計人員調(diào)試的工作量。
本文用了一個具體的FPGA設(shè)計案例,來體現(xiàn)上面提到的NoC在FPGA設(shè)計中的幾項重要作用。這個設(shè)計的主要目的是展示FPGA內(nèi)部的邏輯如何去訪問片外的存儲器。如圖1所示,本設(shè)計包含8個讀寫模塊,這8個讀寫模塊需要訪問8個GDDR6通道,這樣就需要一個8x8的AXI interconnect模塊,同時需要有跨時鐘域的邏輯去將每個GDDR6用戶接口時鐘轉(zhuǎn)換到邏輯主時鐘。除了圖1中的8個讀寫模塊外,紅色區(qū)域的邏輯都需要用FPGA的可編程邏輯去實(shí)現(xiàn)。
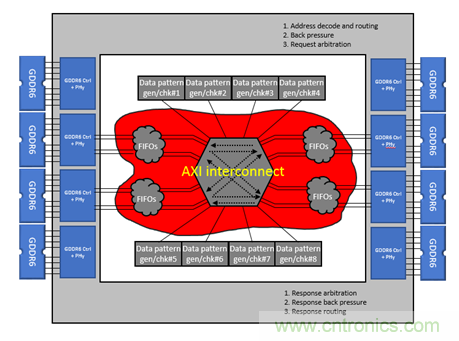
圖1 傳統(tǒng)FPGA實(shí)現(xiàn)架構(gòu)
對于AXI interconnect模塊,我們采用Github上開源的AXI4總線連接器來實(shí)現(xiàn),這個AXI4總線連接器將4個AXI4總線主設(shè)備連接到8個AXI4總線從設(shè)備,源代碼可以在參考文獻(xiàn)2的鏈接中下載。我們在這個代碼的基礎(chǔ)上進(jìn)行擴(kuò)展,增加到8個AXI4總線主設(shè)備連接到8個AXI4總線從設(shè)備,同時加上了跨時鐘域邏輯。
為了進(jìn)行對比,我們用另外一個設(shè)計,目的還是用這8個讀寫模塊去訪問8個GDDR6通道;不同的是,這次我們將8個讀寫模塊連接到Achronix的Speedster7t FPGA器件的2D NoC上,然后通過2D NoC去訪問8個GDDR6通道。如圖2所示:
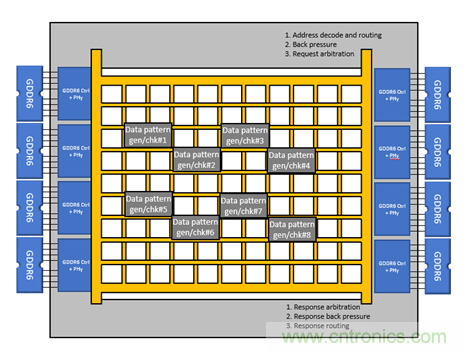
圖2 Speedster7t 1500的實(shí)現(xiàn)架構(gòu)
首先,我們從資源和性能上做一個對比,如圖3所示:
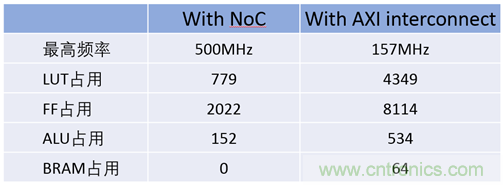
圖3 資源占用和性能對比
從資源占用上看,用AXI總線連接器的設(shè)計會比用2D NoC的設(shè)計占用多出很多的資源,以實(shí)現(xiàn)AXI interconnect還有跨時鐘域的邏輯。這里還要說明一點(diǎn),這個開源的AXI interconnect實(shí)現(xiàn)的是一種最簡單的總線連接器,并不支持2D NoC所能提供的所有功能,比如地址表映射,優(yōu)先級配置。
最重要的一點(diǎn)是AXI interconnect只支持阻塞訪問(blocking),不支持非阻塞訪問(non-blocking)。阻塞訪問是指發(fā)起讀或者寫請求以后,要等到本次讀或者寫操作完成以后,才能發(fā)起下一次的讀或者寫請求。而非阻塞訪問是指可以連續(xù)發(fā)起讀或者寫請求,而不用等待上次的讀或者寫操作完成。在提高GDDR6的訪問效率上面,阻塞訪問會讓讀寫效率大大下降。
如果用FPGA的可編程邏輯去實(shí)現(xiàn)完整的2D NoC功能,包括64個接入點(diǎn)、128bit位寬和400MHz的速率,大概需要850 k LE,等效于占用了Speedster7t 1500 FPGA器件56%的可編程資源。而2D NoC則可以提供 80個接入點(diǎn)、256bit位寬和2GHz速率,而且不占用FPGA可編程邏輯。
從性能上來看,使用AXI總線連接器的設(shè)計只能跑到157MHz,而使用NoC的設(shè)計則能跑到500MHz。如果我們看一下設(shè)計后端的布局布線圖,就會有更深刻的認(rèn)識。圖4所示的是使用AXI總線連接器的設(shè)計后端布局布線圖。
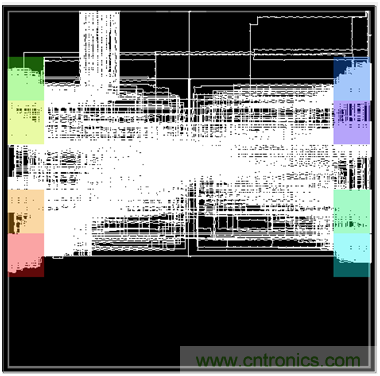
圖4 使用AXI interconnect的設(shè)計后端布局布線圖
從圖中可以看到,因?yàn)镚DDR6控制器分布在器件的兩側(cè)(圖中彩色高亮的部分),所以AXI總線連接器的布局基本分布在器件的中間,既不能靠近左邊,也不能靠近右邊,所以這樣就導(dǎo)致了性能上不去。如果增加pipeline的寄存器可以提高系統(tǒng)的性能,但是這樣會占用大量的寄存器資源,同時會給GDDR的訪問帶來很大的延時。
如果再看一下圖5中使用了2D NoC的布局布線圖,就會有很明顯的對比。首先,因?yàn)橛?D NoC實(shí)現(xiàn)了AXI總線連接器和跨時鐘域的模塊,這就節(jié)省了大量的資源;另外,因?yàn)?D NoC遍布在整個器件上,一共有80個接入點(diǎn),所以8個讀寫模塊可以由工具放置在器件的任何地方,而不影響設(shè)計的性能。
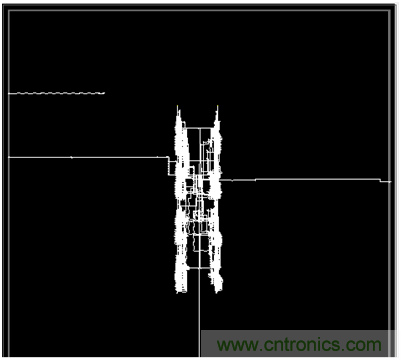
圖5 使用2D NoC設(shè)計的后端布局布線圖
從本設(shè)計的整個流程來看,使用2D NoC會極大的簡化設(shè)計,提高性能,同時節(jié)省大量的資源;FPGA設(shè)計工程師可以花更多的精力在核心模塊或者算法模塊設(shè)計上面,把總線傳輸、外部接口訪問仲裁和接口異步時鐘域的轉(zhuǎn)換等工作全部交給2D NoC吧。
如需了解更多Speedster7t FPGA器件產(chǎn)品細(xì)節(jié),請發(fā)送郵件到Dawson.Guo@Achronix.com,或訪問Achronix公司官方網(wǎng)站:http://www.achronix.com以訂閱新聞和獲取產(chǎn)品資料。
參考文獻(xiàn):
1.使用帶有片上高速網(wǎng)絡(luò)的FPGA的八大好處
2.https://github.com/Verdvana/AXI4_Interconnect
推薦閱讀:



